- Topvisor Help Center /
- Implicit duplicates
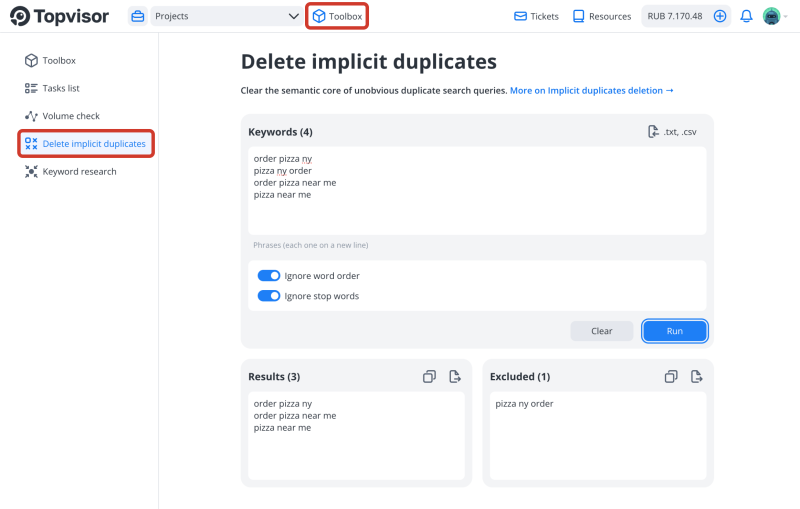
Delete implicit duplicates
After collecting the semantic core, it needs to be cleaned to retain only relevant, targeted keywords for SEO and analytics. A tool for removing implicit duplicates will help quickly clear the core of similar queries that are, however, not exact duplicates.
- Implicit duplicates
- Keywords that consist of the same set of words with different word forms and word orders.
- Complete duplicates: "order pizza ny" и "order pizza in ny"
- Implicit duplicates: "order pizza ny", "ny order pizza", "order a pizza in ny", "order pizza in new york"
Which phrases are considered implicit duplicates
- Which can be normalized to the same form ("order pizza ny", "ordering pizza ny");
- With different word order ("order pizza ny", "ny order pizza");
- Differing only in stop words ("order pizza ny", "order pizza in ny").
Keyword normalization algorithm
The algorithm for detecting implicit duplicates includes keywords normalization. Normalization is performed using stemming and heuristics, but not full lemmatization (reducing a word to its original form). Stemming involves "chopping off" endings and suffixes from words to extract their unchangeable stem. Heuristics are additional algorithms and rules that refine normalization based on accumulated data on user behavior, query frequency, typo correction, synonymy, and context.
First, stemming is used to quickly select similar words. Then, heuristics compare similar phrases with each other and determine which stemming groups are truly equivalent in meaning and which are not.
If, after analysis, several queries are recognized as implicit duplicates, the first canonical phrase encountered will be considered relevant. For example, if you enter queries in this order: "order pizza ny" and "ny pizza order", the phrase "ny pizza order" will be excluded. And if you swap them and enter "ny pizza order" and "order pizza ny", the phrase "order pizza ny" will be excluded.
Tool settings
- Ignore word order — enable this option if you want the algorithm to consider phrases consisting of the same words in different orders as implicit duplicates. For example, "order pizza ny" and "ny order pizza" will be considered different queries with this option disabled, but with this option enabled, they will be implicit duplicates, and the second phrase will be excluded;
- Ignore stop words — enable this option if you want the algorithm to ignore stop words when normalizing keywords. If you enable this setting and run implicit duplicate removal for the keywords "order pizza ny" and "order pizza in ny", the stop word "in" will be ignored before normalization. That is, the algorithm will compare the queries "order pizza ny" and "order pizza ny". The second query will be considered an implicit duplicate and excluded. If this option is disabled, the phrases "order pizza ny" and "order pizza in ny" will be normalized without excluding any words from the queries and will not be considered implicit duplicates.
Does the tool use search volume to determine which version of a keyword should be kept?
After cleaning up the implicit duplicates, I still have a lot of similar keywords. How else can I clean up the semantics?
What words are considered stop words?
a about all am an and any are as at be been but by can cans could do dost did for from had has have her hers i if in is it me misin miyim my no not of on one or so that the them there they this to was we were what which will with would you а будем будет будете будешь буду будут будучи будь будьте бы был была были было быть в вам вами вас весь во вот все всё всего всей всем всём всеми всему всех всею всея всю вся вы да для до его едим едят ее её ей ел ела ем ему емъ если ест есть ешь еще ещё ею же за и из или им ими имъ их к как кем ко когда кого ком кому комья которая которого которое которой котором которому которою которую которые который которым которыми которых кто меня мне мной мною мог моги могите могла могли могло могу могут мое моё моего моей моем моём моему моею можем может можете можешь мои мой моим моими моих мочь мою моя мы на нам нами нас наса наш наша наше нашего нашей нашем нашему нашею наши нашим нашими наших нашу не него нее неё ней нем нём нему нет нею ним ними них но о об один одна одни одним одними одних одно одного одной одном одному одною одну он она оне они оно от по при с сам сама сами самим самими самих само самого самом самому саму свое своё своего своей своем своём своему своею свои свой своим своими своих свою своя себе себя собой собою та так такая такие таким такими таких такого такое такой такому такою такую те тебе тебя тем теми тех то тобой тобою того той только том томах тому тот тою ту ты у уже чего чем чём чему что чтобы эта эти этим этими этих это этого этой этом этому этот этою эту я мені наші нашої нашій нашою нашім ті тієї тією тії теє