- Справочный центр /
- Удаление неявных дублей
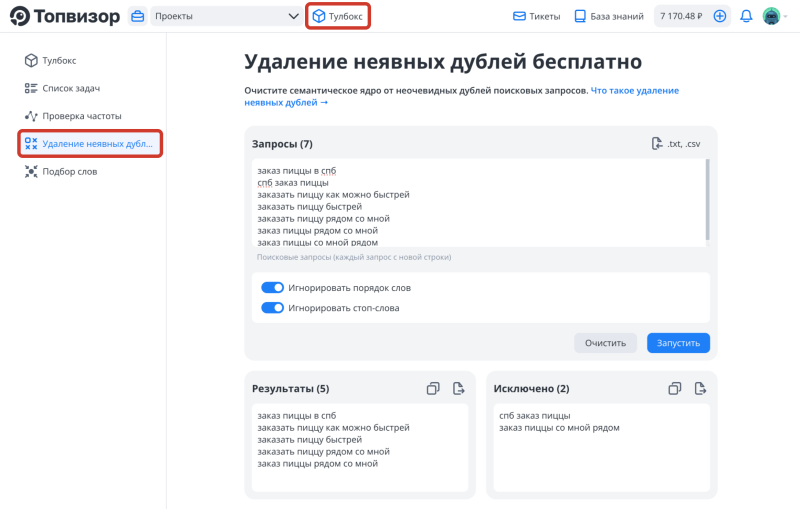
Удаление неявных дублей
После сбора семантического ядра его нужно почистить, чтобы оставить для продвижения и аналитики только релевантные, целевые запросы. Инструмент для удаления неявных дублей поможет быстро очистить ядро от похожих запросов, которые, тем не менее, не являются полными дублями друг друга.
Читайте, как понять, от каких запросов нужно чистить ядро, в Топвизор‑Журнале →
- Неявные дубли
- Запросы, которые состоят из одинакового набора слов с разной словоформой и порядком слов.
- Полные дубли: "заказать пиццу в спб" и "заказать пиццу в спб"
- Неявные дубли: "заказать пиццу в спб", "в спб пиццу заказать", "заказывать пиццу в спб", "заказать пиццу санкт петербург"
Какие фразы считаются неявными дублями
- Которые можно нормализовать до одинакового вида ("заказ пиццы в спб", "заказы пиццы в спб");
- С разным порядком слов ("заказать пиццу в спб", "в спб пиццу заказать");
- Отличающиеся только стоп‑словами ("заказать пиццу в спб", "заказать пиццу спб").
Алгоритм нормализации запросов
Алгоритм выявления неявных дублей включает в себя нормализацию запросов. Нормализация выполняется на основе стемминга и эвристики, но не полной лемматизации (приведения слова к исходной форме). Стемминг заключается в "обрубании" у слов окончаний и суффиксов для выделения их неизменяемой основы. Эвристики — это дополнительные алгоритмы и правила, которые уточняют нормализацию, опираясь на накопленные данные о поведении пользователей, употребительности запросов, исправлении опечаток, синонимии и контексте.
Сначала применяется стемминг для быстрого отбора похожих слов. Затем эвристики сравнивают похожие запросы между собой и уточняют, какие из стемминг‑групп действительно эквивалентны по смыслу, а какие нет.
Если после анализа несколько запросов признаны неявными дублями, актуальной будет считаться первая встретившаяся каноническая фраза. Например, если ввести запросы в таком порядке: "в спб пиццу заказать" и "заказать пиццу в спб", исключена будет фраза "заказать пиццу в спб". А если поменять их местами и ввести "заказать пиццу в спб" и "в спб пиццу заказать", исключена будет фраза "в спб пиццу заказать".
Настройки инструмента
- Игнорировать порядок слов — включите эту опцию, если вы хотите, чтобы алгоритм считал неявными дублями запросы, состоящие из одинаковых слов, стоящих в разном порядке. К примеру, "заказать пиццу в спб" и "в спб пиццу заказать" с отключенной опцией будут считаться разными запросами, а с включенной — неявными дублями, и второй запрос будет исключен;
- Игнорировать стоп‑слова — включите эту опцию, если вы хотите, чтобы алгоритм игнорировал стоп‑слова при нормализации запросов. Если включить настройку и запустить удаление неявных дублей для запросов "заказать пиццу в спб" и "заказать пиццу спб", стоп‑слово "в" будет проигнорировано перед нормализацией. То есть алгоритм будет сравнивать запросы "заказать пиццу спб" и "заказать пиццу спб". Второй по порядку запрос будет признан неявным дублем и исключен. Если же опция выключена, то фразы "заказать пиццу в спб" и "заказать пиццу спб" будут нормализованы без исключения каких‑либо слов из запросов и не будут считаться неявными дублями.
Инструмент использует частоту запросов, чтобы определить, какой вариант фразы стоит оставить?
После чистки неявных дублей у меня всё равно осталось много похожих запросов. Как можно ещё почистить ядро?
Какие слова считаются стоп‑словами?
a about all am an and any are as at be been but by can cans could do dost did for from had has have her hers i if in is it me misin miyim my no not of on one or so that the them there they this to was we were what which will with would you а будем будет будете будешь буду будут будучи будь будьте бы был была были было быть в вам вами вас весь во вот все всё всего всей всем всём всеми всему всех всею всея всю вся вы да для до его едим едят ее её ей ел ела ем ему емъ если ест есть ешь еще ещё ею же за и из или им ими имъ их к как кем ко когда кого ком кому комья которая которого которое которой котором которому которою которую которые который которым которыми которых кто меня мне мной мною мог моги могите могла могли могло могу могут мое моё моего моей моем моём моему моею можем может можете можешь мои мой моим моими моих мочь мою моя мы на нам нами нас наса наш наша наше нашего нашей нашем нашему нашею наши нашим нашими наших нашу не него нее неё ней нем нём нему нет нею ним ними них но о об один одна одни одним одними одних одно одного одной одном одному одною одну он она оне они оно от по при с сам сама сами самим самими самих само самого самом самому саму свое своё своего своей своем своём своему своею свои свой своим своими своих свою своя себе себя собой собою та так такая такие таким такими таких такого такое такой такому такою такую те тебе тебя тем теми тех то тобой тобою того той только том томах тому тот тою ту ты у уже чего чем чём чему что чтобы эта эти этим этими этих это этого этой этом этому этот этою эту я мені наші нашої нашій нашою нашім ті тієї тією тії теє